self-attention、transformer解读
背景
之前用在NLP上,现在又用到语音、CV上,推荐场景也有用到。
面试考了几次,我最近甚至仍有答错之处,那行,我彻底花点时间来整理一下,尽管网上有N多博客,N多解读,但看了好多,仍然没有彻底攻下,所以我还是以输出倒闭输入来完成对知识的吸收和理解。
(我会慢慢一轮一轮地完善本文的)
模型详解
相关资源推荐
transformer是在论文《Attention is all you need》里面把self-attention发扬光大,说实话,该文其实对新手非常不友好,强烈推荐以李宏毅为首的资源:
- 台大李宏毅自注意力机制和Transformer详解 The Illustrated Transformer
ps: 李宏毅的课程ppt可以在其主页下载——self-attention课件,transformer课件 某知乎用户 的解答还不错,给我补充了不少东西
一开始不可能深入代码细节,我当初看论文的时候也看得云里雾里,看了N多博客也似懂非懂,所以还是从看最好的资源入手。
注意: 我几乎完全参考了李宏毅的视频,所以非重点内容已经把标题置为斜体了。从0开始看应该问题不大。
self-attention
input、output
如何把把一个词汇表示成一个向量呢,最简单做法是One-hot Encoding,这种做法没有包含语义信息,比如,cat分别和dog、apple做点积,结果都是0,但从语义上来说,cat和dog应该是更接近的,另外一种做法是用Word Embedding,先挖个坑。
可以作为input的东西很多,如语言,语音(10ms用某种方法采样为一个向量),分子
输入和输出的长度:
输入为N,输出为N,输出如果是一个数字,那就是回归问题,如果是一个label,那就是分类问题。如POS tagging问题(词性标注)。
输入为N,输出为1,如根据一段话,判断是谁说的;或者输入一个分子,判断是否有毒性。
输入为N,输出不确定,由机器自己决定,如翻译任务,seq2seq任务。
输入输出等长,又叫Sequence Labeling问题。要注意,输入一排向量,长度是不确定的。
fully connected这里没搞懂,参数共享不,再挖个坑
结构
输入是向量,输出也是向量(大小和输入一致)。 然后后面你可以丢到一个FC里面,得到标签,解决分类问题。

self-attention + FC可以叠加多个,经过第一个FC的输出,可以作为下一个self-attention的输入。

计算权重
经过self-attention,从输入到输出,你的每一个输出都是考虑了每一个输入的。所以,对于a1,

用矩阵来解决,最终只需要学习的参数是Wq Wk Wv

Multi-head Self-attention
多头操作,q 出来以后乘以两个矩阵,得到qi1 qi2,k 和 v 是一样的,然后分别单独求出输出,bi1 bi2,拼起来再经过一个矩阵 W0 得到最终输出。多头的数量,也是需要调的参数。

position
提前加进去即可。位置向量可以手工,可以学习得到,并不一定要采用transformer那篇文章的方法,关于这个问题有很多研究的,见下图2。


其他应用
self-attention 用在语音和cv上现在也很常见。
RNN v.s. self-attention:单向的RNN,你每一个输出只考虑了前面的输入,但是self-attention考虑了整个输入。如果是双向,尽管不存在这个问题,也有别的问题,比如——你输入序列的最后一个embedding,如果要考虑第一个embedding,那第一个embedding得逐个传下去不消失,耗时长。self-attention,直接操作就行了。RNN也无法平行处理所有的数据,运算效率比较低。更多比较可以参考Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention (一般来说我都没看,先留个记录,以备不时之需)
self-attention for Graph 应用也出现了
图神经网络参考:Graph Neural Network (1/2)、Graph Neural Network (2/2)
- Long Range Arena: A Benchmark for Efficient Transformers
- Efficient Transformers: A Survey
Transformer
神图
神图先放,慢慢解释

Seq2seq 的广泛应用
transformer本质上是一个Seq2seq的模型,常见任务比如机器翻译、语音识别、语音合成、聊天机器人等等都是Seq2seq任务,输出的长度由模型来决定,提前未知。很多别的任务都可以用Seq2seq来解决,但是,或许针对特定任务设定特定模型会取得比Seq2seq更好的结果。
QA:
The Natural Language Decathlon: Multitask Learning as Question Answering
LAMOL: LAnguage MOdeling for Lifelong Language LearningSyntactic Parsing (参考文章:Grammar as a Foreign Language)

Multi-label Classification
注意和 Multi-class Classification 区别,前者的意思是某个输入可以属于多个类别,而且类别数未知。

Object Detection

Seq2seq 的网络结构
起源于 Sequence to Sequence Learning with Neural Networks 一文,是为了解决机器翻译问题。

Encoder
输入一排向量,输出另外一排向量。

Encoder 可以用 RNN 或者 CNN,也可以用 self-attention 来实现。
self-attention 具体操作的时候,输入经过多个 block 后才得到输出(经过第一个 Block 后得到的输出作为下一个 Block 的输入,最后一个 Block 的输出作为最终输出),每个 block 是由多个 lay 来组成,下图中每个 Block 的操作具体如图右所示。

具体的操作如下,图非常清晰了,残差和 norm 的做法也指出了:

Layer Normalization 不用考虑 batch 的资讯, 输入一个向量,经过 Norm,输出另一个向量,操作的时候计算输入向量的均值和方差。
关于 lay normalization 和 batch normalization 的详细区别,再挖个坑,简单来说是 Batch Normolization 对一批数据的同一维度做归一化,Layer Normolization 是对同一样本的不同维度进行归一化,和batch无关。
关于 Layer Norm 的操作放在哪个位置更好,以及思考 normalization 的方式,以下文章有探讨。

Decoder
注:斜体标题不是重点。
autoregressive(自回归)
上一时刻的输出会当作下一时刻的输入。

把中间遮住,除了一个 Masked 的操作,decoder 其实和 encoder 是一样的。

Masked Self-attention
Masked 的操作很简单,attention 的时候只考虑左边的东西,不考虑右边的东西。就是你当前求 a1 的输出 b1 时,只能看到 a1,求 b2,只能看到 a1、a2。原因其实很简单,你输出的时候,是一个一个出来的,你输出b2的时候,你是没有a3、a4……的。

如何停下来?最后一个输出是 end,出现 end 就停止

Encoder 和 Decoder 的交互
上文 decoder 被遮住的部分,其实是一个 cross attention,有两个输入来自 encoder,有一个输入来自 decoder,具体实现如下图

接下来的第二个输出的操作是一样的,如下图所示

Non-autoregressive (NAT)
两种方法来决定输出:1.把encoder的输出吃进一个classical求得一个长度,由这个长度来决定decoder的输出的长度。2.假设按经验最长就是300了,全部输进去,输出的时候,找到end,舍弃掉end右端的。
NAT的好处:1.并行,不用像AT那样一个一个地输出(需要做多次decoder操作),因此速度比AT快。2.能更好地控制输出的长度。
NAT的缺陷:表现不如AT,原因是 Multi-modality,NAT参考视频。

cross attention的历史及其他操作
关于 cross attention,这个之前就有了,模型表现,吐出每一个字母时,关注范围从坐上到右下,很符合直觉。

cross attention,transformer里面,encoder和decoder都有多层,但是每层decoder都是使用encoder最后一层的输出的。但其实可以考虑用encoder非最后一层的输出来作为输入的。

训练
机被表示成一个one-hot的向量,只有机对应的那个维度为1,其余为0,这是正确答案。decoder的输出是一个distribution,是一个概率的分布,希望这个分布和one-hot越接近越好,所以计算cross entropy(交叉熵),希望这个值越小越好,该问题和分类很像。最后end也要计算,把5下图所示的5个交叉熵加起来,目标是最小化交叉熵和。


这里面还有一个 Teacher Forcing 的说法,如上图所示。
tips
Copy Mechanism
Chat-bot
比如在对话机器人中,有些奇怪的名词不需要生成,可以直接使用拷贝。

summarization
通常需要百万篇文章才够!所以之前做的病例生成项目,是无法使用端到端的模型来解决的。
参考:
文章:Get To The Point: Summarization with Pointer-Generator Networks
文章:Incorporating Copying Mechanism in Sequence-to-Sequence Learning

guided attention
Monotonic attention、Location-aware attention
Beam Search
简单说就是不必找所有路径。参考 The Curious Case of Neural Text Degeneration
opimizing evaluation metrics
训练的时候是 cross attention,所以是每个单独算loss,但是BLUE score是整体的,如何在训练的时候也用BLUE score来评估呢?*当你不知道怎么样optmize的时候,可以考虑reinforcement learning(RL, 强化学习),参考 Sequence Level Training with Recurrent Neural Networks

exposure bias
解决办法是给decoder的输入加一些错误的东西

scheduled sampling,参考方法如下

挖坑
检索文章“挖个坑”,如下:
fully connected 这里没搞懂,参数共享不。逐位的FNN?
每一层经过attention之后,还会有一个FFN,这个FFN的作用就是空间变换。FFN包含了2层linear transformation层,中间的激活函数是ReLu。引入了非线性(ReLu激活函数),变换了attention output的空间, 从而增加了模型的表现能力。把FFN去掉模型也是可以用的,但是效果差了很多。
lay normalization 和 batch normalization 的详细区别
维度问题,Wq,Wk,Wv 三个参数是共享的吗?确认下
$W_{i}^{Q} \in \mathbb{R}^{d_{\text {model }} \times d_{k}}, W_{i}^{K} \in \mathbb{R}^{d_{\text {model }} \times d_{k}}, W_{i}^{V} \in \mathbb{R}^{d_{\text {model }} \times d_{v}}$
但是大小还没解决。
或许可以参考 链接1:Q,K,V进行了很详细的讲解 参考2
Positional Encoding
- embedding 层的参数需要在训练中学习吗
里面的矩阵操作,具体顺序,维度变化。
线性代数挖个坑吧,以后补一下,有很好的课程的。
- 残差 —— https://zhuanlan.zhihu.com/p/80226180?utm_source=wechat_session
补充Tips
矩阵的点乘
矩阵第m行与第n列交叉位置的那个值,等于第一个矩阵第m行与第二个矩阵第n列,对应位置的每个值的乘积之和。矩阵的本质就是线性方程式,两者是一一对应关系。
关于超参数

mask
Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
padding mask:每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0。
Sequence mask:time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
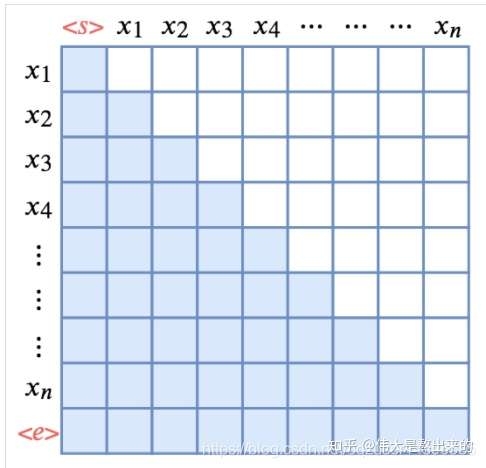
对于 decoder 的 self-attention,里面使用到的 scaled dot-product attention,同时需要padding mask 和 sequence mask 作为 attn_mask,具体实现就是两个mask相加作为attn_mask。其他情况,attn_mask 一律等于 padding mask。参考
Linear & Softmax
Decoder最后是一个线性变换和softmax层。解码组件最后会输出一个实数向量。我们如何把浮点数变成一个单词?这便是线性变换层要做的工作,它之后就是Softmax层。
线性变换层是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数(相当于做vocaburary_size大小的分类)。接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。 参考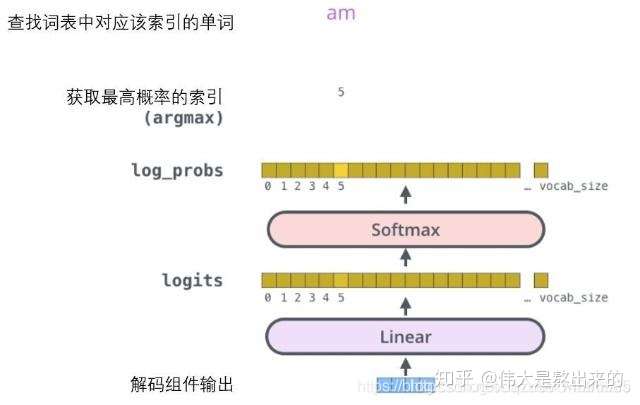
常见面试问答
为什么Transformer中K 、Q不能使用同一个值 参考
为什么不直接使用$X$而要对其进行线性变换(通过Wq,Wk,Wv 得到q k v)
为了提升模型的拟合能力,矩阵Wq,Wk,Wv 都是可以训练的,起到一个缓冲的效果。
$\sqrt{d_{k}}$ 的意义

Multi-Head Attention 怎么操作的(腾讯ieg游戏广告部门问到,答错了,一面挂)
通过权重矩阵
将
分割,每个头分别计算 single self-attention,因为权重矩阵
的结果各不相同,因此我们说每个头的关注点各有侧重。最后,将每个头计算出的 single self-attention进行concat,通过总的权重矩阵$W^{O}$决定对每个头的关注程度,从而能够做到在不同语境下对相同句子进行不同理解。参考
softmax的维度
![[公式]](/img/loading.gif) 将
将Layer Normalization作用,以及为什么不用 Batch Normalization
$L N\left(x_{i}\right)=\alpha \frac{x_{i}-\mu_{i}}{\sqrt{\sigma^{2}+\xi}}+\beta$,作用是规范优化空间,加速收敛。我们使用梯度下降算法做优化时,我们可能会对输入数据进行归一化,但是经过网络层作用后,我们的数据已经不是归一化的了。随着网络层数的增加,数据分布不断发生变化,偏差越来越大,导致我们不得不使用更小的学习率来稳定梯度。Layer Normalization 的作用就是保证数据特征分布的稳定性,将数据标准化到ReLU激活函数的作用区域,可以使得激活函数更好的发挥作用。参考
Residual Network 残差网络
在神经网络可以收敛的前提下,随着网络深度的增加,网络表现先是逐渐增加至饱和,然后迅速下降,这就是我们经常讨论的网络退化问题,为了使当模型中的层数较深时仍然能得到较好的训练效果,模型中引入了残差网络。暂时回答解决梯度消失问题。
Transformer相比于RNN/LSTM,有什么优势
RNN系列的模型,并行计算能力很差。RNN并行计算的问题就出在这里,因为 T 时刻的计算依赖 T-1 时刻的隐层计算结果,而 T-1 时刻的计算依赖 T-2 时刻的隐层计算结果,如此下去就形成了所谓的序列依赖关系。
Transformer的特征抽取能力比RNN系列的模型要好。
具体实验对比可以参考:放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较scaled
$\sqrt{d}$ 代表 $k^{i}$ 的维度,除以$\sqrt{d}$ 的原因是:进行点乘后的数值很大,导致通过softmax后梯度变的很小,所以通过除以$\sqrt{d}$ 来进行缩放。
代码细节
待续……
看源码就知道很多细节了,一定要看,欠账必还。
看下 https://zhuanlan.zhihu.com/p/411311520
参考
- ……
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!